I dagens snabbrörliga juridiska miljö är det avgörande att extrahera kritisk information för att säkra regelefterlevnad och effektivisera arbetsflöden, minska manuellt arbete och förbättra insynen i och tillgängligheten till avtal. Att extrahera viktig och kritisk data från olika textkällor har länge varit ett stort problem, särskilt inom juridik, där central information som parter, tillämplig lag, datum för underrättelse, avtalsvärde och liknande har olika juridiska konsekvenser. Innan stora språkmodeller (LLM:er) var traditionella NLP-baserade tekniker för namngiven entitetsigenkänning standardlösningen. Med LLM:er kan vi extrahera kritisk juridisk information med ett klick för att förbättra din sök- och filtreringsupplevelse i Miramis-plattformen (tidigare Pocketlaw). I den här artikeln går vi igenom hur AI snabbt kan extrahera nyckeldata ur avtal, varför kontextuell relevans är avgörande inom juridik, vilken kritisk roll mänsklig granskning spelar och hur Miramis kan förändra hur du arbetar med datainsikter.
1. Hur kan AI hjälpa till med metadataextraktion
LLM:er är mycket bra på att extrahera olika metadataegenskaper från en textkälla, ofta ett avtal, i juridiska sammanhang. Tack vare sin träning är de särskilt skickliga på att känna igen och extrahera viktiga namngivna entiteter ur ett avtal.
Named Entity Recognition (NER) är en uppgift inom Natural Language Processing (NLP) som handlar om att identifiera och klassificera namngivna entiteter i en text i fördefinierade kategorier, som personnamn, organisationer, platser med mera. Målet med NER är att extrahera strukturerad information från ostrukturerad textdata och representera den i ett maskinläsbart format. Metoderna använder vanligtvis BIO-notation, där man skiljer mellan början av en entitet (B) och inuti en entitet (I). O används för token som inte tillhör någon entitet. Ett exempel från ett juridiskt dokument kan vara:
“Detta avtal, daterat den 1 januari 2024, ingås mellan Acme Corporation och John Smith.”
Detta skulle ge följande entiteter:
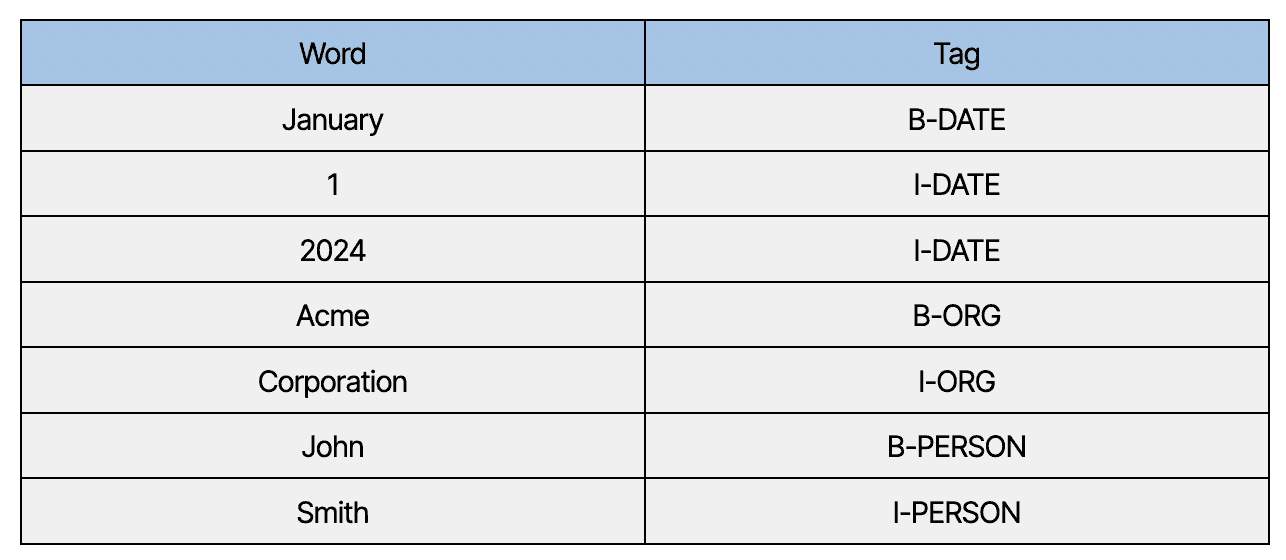
DATUM: “1 januari 2024” – Början (B) av datumet är “januari”, följt av inuti-taggar (I) för “1” och “2024”.
ORG (Organisation): “Acme Corporation” – “Acme” är början på organisationsnamnet, och “Corporation” är den inre delen.
PERSON: “John Smith” – “John” är början, och “Smith” är den inre delen av personens namn.
Den här strukturerade taggningen (med BIO-notation) gör att vi kan mappa ostrukturerad text till sökbara metadatafält. Traditionella NER-metoder kräver omfattande annoterade dataset och stora tekniska insatser för att nå hög precision. LLM:er kan däremot utföra uppgiften träffsäkert med minimal uppsättning, snabbt identifiera entiteter och anpassa sig till komplex juridisk språkdräkt.
När du använder LLM:er för metadataextraktion blir juridiska arbetsflöden smidigare, och det går snabbare och enklare att hitta kritisk information i stora dokumentsamlingar. Det förändrar hur jurister arbetar med avtalsdata.
2. Viktiga saker att tänka på för en AI-lösning för automatisk taggning
Nu när vi vet hur AI kan extrahera kritisk information från juridiska dokument och hur informationen kan användas, kan vi gå in på några viktiga saker att tänka på för en juridisk AI-lösning för automatisk taggning.
2.1 Noggrannhet och precision
Hög träffsäkerhet i taggningen är avgörande i juridiska tillämpningar, eftersom felaktig taggning kan leda till betydande risker, från feltolkade villkor till förbisedda klausuler som kan få ekonomiska eller juridiska konsekvenser. Mer konkret bör lösningen kunna:
Minimera falska positiva (felaktigt taggade entiteter) och falska negativa (missade entiteter)
Hantera olika juridiska termer och nyanserade språkvariationer korrekt
Stödjas av rigorös testning med juridiska dataset kuraterade för domänen för att löpande förbättra noggrannhet och precision.
På Miramis är detta en del av vårt modus operandi. Tillsammans med våra domänexperter ser vi till att vår taggningslösning är juridiskt hållbar och träffsäker. Det här kontinuerliga arbetet har förstås gjort vår repository-lösning bäst i klassen.
2.2 Språk-, avtals- och jurisdiktionsagnostisk
En effektiv AI-lösning måste vara flexibel och kunna hantera dokument på olika språk, avtalstyper och jurisdiktioner. Juridiska termer och tolkningar kan också variera. Några viktiga aspekter vi ser är:
Den stöder flera språk och går att anpassa för användning på olika språk.
Den fungerar sömlöst med olika avtalstyper, från NDA:er till marknadsföringsavtal.
Den känner igen skillnader mellan jurisdiktioner och anpassar taggningen därefter.
På Miramis använder vi de senaste och bästa LLM:erna med bred språkförmåga, från svenska och engelska till arabiska och många andra språk.
2.3 Hantera tvetydighet och varierande kontext
Juridiskt språk är ofta starkt kontextberoende och tvetydigt, och termer kan ha olika betydelser och konsekvenser beroende på sammanhanget. Till exempel kan “ikraftträdandedatum” betyda olika saker beroende på om avtalet är ett anställningsavtal, ett försäljningsavtal eller ett NDA. En robust AI-taggning bör:
Upptäcka subtila kontextskiften i dokument för att tagga entiteter korrekt.
Anpassa sig till olika dokumentkategorier och klausuler utan rigida mallar eller exempel.
Utnyttja och förstå dokumentets semantik och kontext utifrån omgivande text eller intilliggande dokument.
På Miramis använder vi de senaste och bästa LLM:erna, arbetar med marknadsledande prompt engineering techniques och förfinar den kontext som används för att extrahera och hantera juridiska nyanser i avtal. Det här gör vi tillsammans med våra juridiska domänexperter. Det är lätt att tro att det räcker att ge LLM:en ett exempelschema för vad den ska extrahera. Vår erfarenhet är att detta inte räcker i juridisk praktik. I bästa fall kan du komma 80 % av vägen, men för att nå upp i höga 90-tal när det gäller precision krävs betydligt mer arbete för att säkerställa den bästa upplevelsen för dig och ditt juridiska team.
2.4 Tolkningsbarhet och transparens i modellen
Transparens är avgörande i juridiska tillämpningar, eftersom yrkesverksamma måste kunna lita på AI:ns taggningsbeslut. Lösningen bör göra det möjligt för användare att förstå resonemanget bakom varför vissa taggar extraheras, vilket stärker både förtroende och användbarhet. Viktiga aspekter är:
Ge tydliga förklaringar och resonemang till varför specifika entiteter taggas, särskilt vid tvetydiga termer.
Användare kan granska, verifiera och justera taggar med minimal insats när det behövs.
Lösningen bör ge hänvisningar och referenser till var entiteten extraherades i dokumentet.
Dessa centrala funktioner är ett måste hos Miramis för att stärka förtroendet och användbarheten i dessa AI- och LLM-baserade system. Vi triggar inga arbetsflöden och uppdaterar inte vår sökmotor förrän du har bekräftat att taggarna motsvarar dina förväntningar, vilket ger dig mer kontroll och kraft. På så sätt minimeras risken för felaktig extraktion som kan leda till kostsamma juridiska misstag.
2.5 Integration med befintliga arbetsflöden
För att en AI-lösning för taggning ska vara värdefull måste den passa sömlöst in i befintliga juridiska arbetsflöden. Juridiska team kan vara djupt förankrade i specifika dokumenthanterings- eller avtalshanteringssystem, där AI-lösningen för taggning bör:
Integreras smidigt med vanliga juridiska plattformar, dokumenthanteringssystem och CLM-system.
Minimera störningar genom att anpassa sig till etablerade processer för dokumentgranskning, lagring och återhämtning.
Skapa handlingsbara insikter och anpassade dashboards med hjälp av metadata-taggarna.
Vi har byggt Miramis som en helhetslösning för din CLM, som drivs av våra AI-funktioner. För att stötta dig genom hela dokumentlivscykeln, från att skapa en mall, skriva ett dokument, ta emot, skicka eller redigera avtal med andra parter, signera avtal och extrahera metadata ur avtal. Detta görs för att (1) indexera dem på vår plattform, (2) göra dem sökbara för dig och (3) använda kritisk metadata för handlingsbara insikter, från att sätta upp aviseringar till att bygga anpassade dashboards.
Med dessa funktioner blir metadataextraktion bara en del av en komplett lösning som ger juridiska team möjlighet att fatta datadrivna beslut genom hela avtalslivscykeln.
2.6 Hantera stora dokumentvolymer
Att hantera stora dokumentvolymer kräver att AI bibehåller effektivitet och precision även vid hög volym av avtal, så att även bulkbearbetning ger tillförlitlig och användbar metadata. Viktiga aspekter är:
Att kunna tagga ett eller många dokument inom rimlig tid
Att kunna extrahera text från olika dokumenttyper som PDF, docx osv.
Att kunna köra om taggningen för dokument när det behövs
På Miramis är storskalig bearbetning en del av vårt DNA. Vår AI-lösning för automatisk taggning fungerar lika bra på ett dokument som på 1000-tals dokument av olika typer, som PDF och docx. Vår pipeline för textextraktion säkerställer att all kritisk information i ett dokument tas in och förbereds för metadataextraktion, oavsett om det handlar om bilder, tabeller eller blandat format i ett specifikt dokument.
3. Hur Miramis (tidigare Miramis) extraherar kritisk juridisk metadata i stor skala
På Miramis använder vi banbrytande teknik, som de senaste LLM:erna, tillsammans med juridisk domänexpertis för att säkerställa att metadataextraktion är effektiv, skalbar och mycket träffsäker. Nedan går vi djupare in i hur vi gör detta på Miramis.
3.1 Stöd för många juridiska metadataegenskaper
På Miramis stödjer vi många relevanta juridiska metadataegenskaper, från dokumentkategori, parter och uppsägningstid till prövotid. Många av dessa egenskaper går också att AI-tagga, och vi stödjer AI-baserad taggningsextraktion för tusentals dokument.
Se exemplet nedan för hur detta ser ut i plattformen.
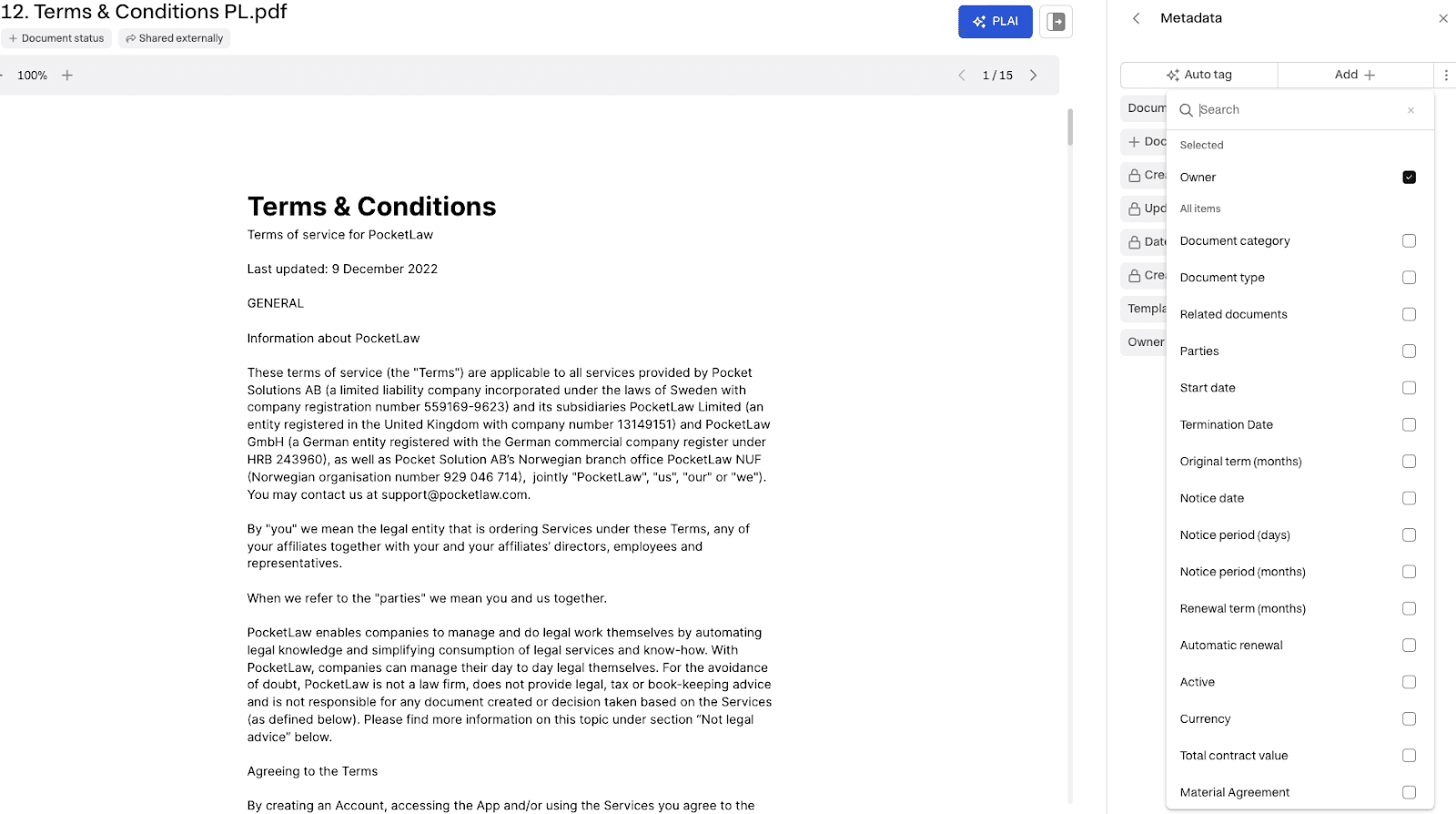
Figur 1. Exempel på tillgängliga taggar.
Som du ser sätts vissa taggar så fort du laddar upp ett dokument, vilket vi kallar systemset properties. Det är olika metadataegenskaper som ingår i dokumentets metadata när det laddas in i Miramis-plattformen. Utöver de systemset-egenskaperna kan du lägga till vilken egenskap som helst i rullistan. Majoriteten av dem taggas också automatiskt av AI.
När AI-taggar läggs till ser du dem i lila nedan för vidare åtgärder:
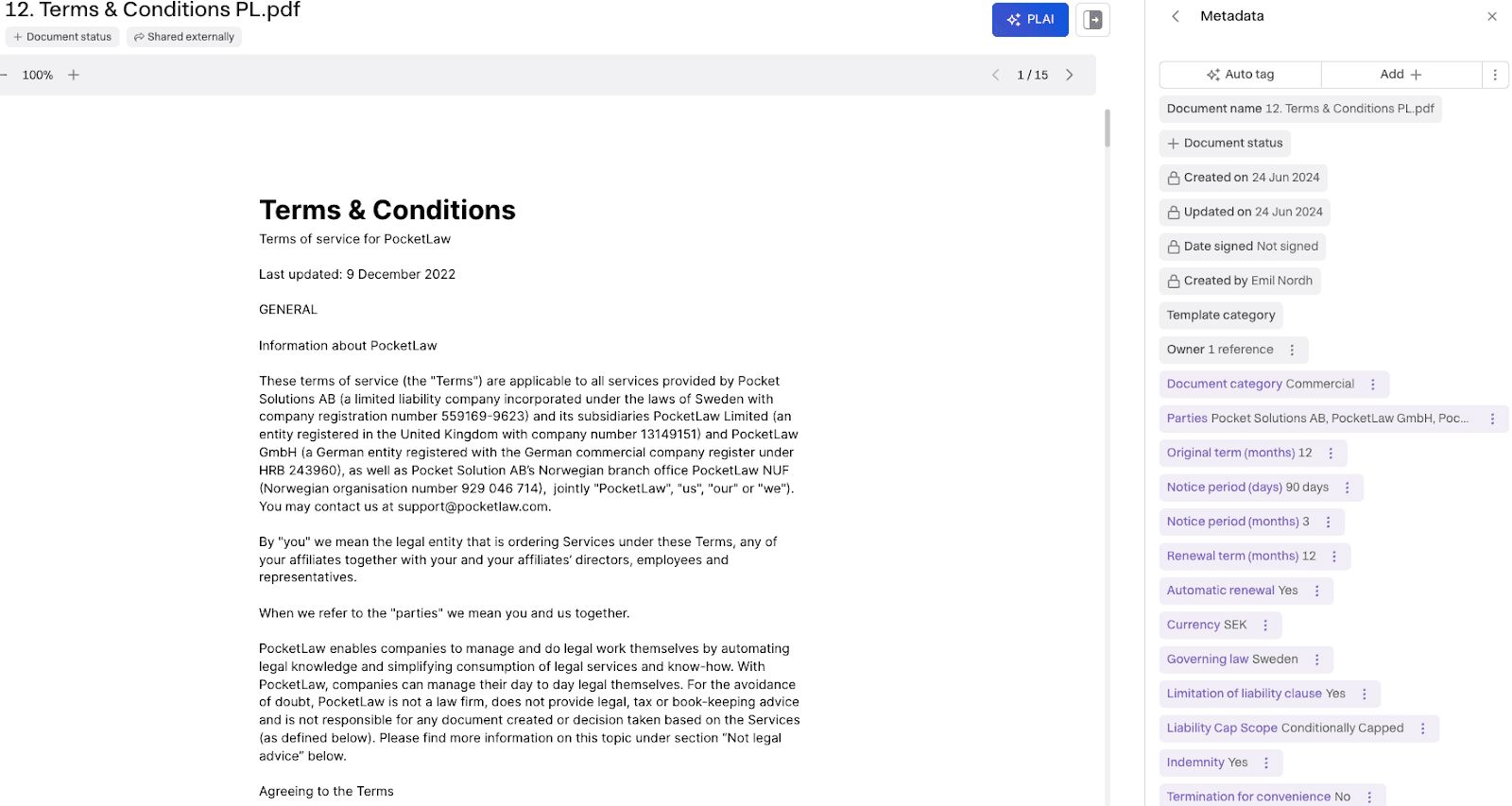
Figur 2. AI-autotaggade taggar visas i lila.
3.2 Användning av avancerade prompt engineering-tekniker
För att nå högsta möjliga precision när vi använder LLM:er för att extrahera metadata använder vi ett brett spektrum av prompt engineering-tekniker och guardrails för att säkra högsta kvalitet i varje extraktion. Även om de flesta LLM-leverantörer stödjer extraktion av strukturerad output (se till exempel OpenAI:s relativt nya tillkännagivande) från ett JSON-schema, har vi i juridiska sammanhang sett att det krävs mer än att bara tillhandahålla schemat för att nå högsta noggrannhet och precision.
Några av teknikerna vi använder är:
Att inkludera domänkunskap för varje egenskap med few-shot-exempel
Chain-of-Thought-resonemang
Prompt Chaining för att dela upp extraktionsproblemet i delproblem
Self-consistency, reflektion och korrigering
Detta, tillsammans med olika guardrails, är implementerat i vår backend för att minimera och motverka potentiella fel och hallucinationer. Med de här teknikerna har vi nått hög precision för ett brett spann av egenskaper och dokumentkategorier.
3.3 Human-in-the-loop-verifiering hela tiden
För att öka systemets tillförlitlighet och förtroendet för det använder vi också följande för dig som slutanvändare:
Varje tagg behöver verifieras innan den kan indexeras och användas i vår sökmotor
Alla taggar har ett resonemangs- och citeringsfält som gör verifieringen smidig
Så här ser det ut i plattformen för dessa olika mekanismer:
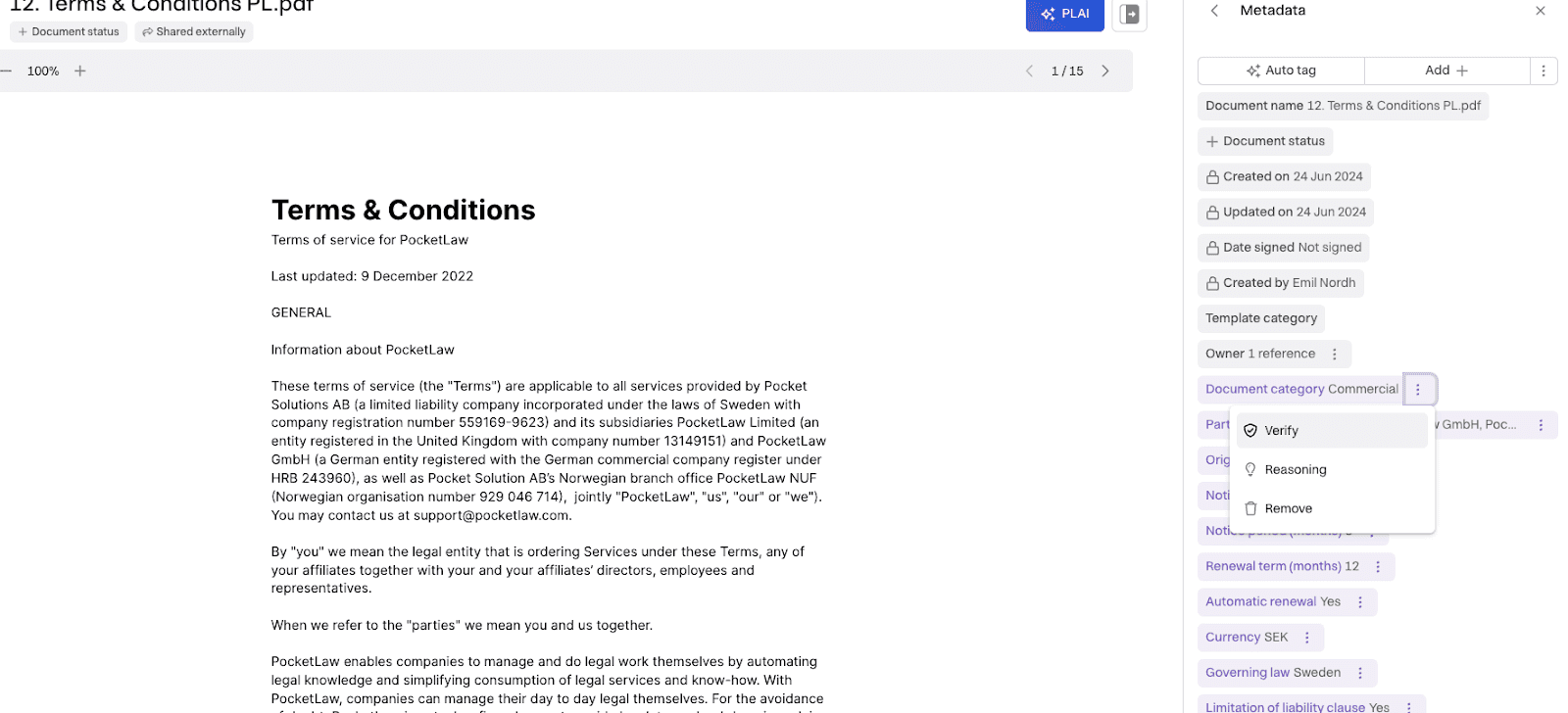
Figur 3. Human-in-the-loop-kontroller för metadata-taggar.
Du kan verifiera, visa resonemang eller ta bort AI-taggen genom att klicka på de tre punkterna. Verifiera används för att verifiera AI-taggen; resonemang visar resonemanget och en hänvisning om sådan finns. Slutligen används ta bort för att ta bort taggen. Det kan vara praktiskt om du till exempel vill tagga om allt i ett dokument som redan har verifierats, om dokumentets kontext har förändrats kraftigt.
När du klickar på verifiera blir taggen grå, vilket motsvarar systemset-egenskaperna, och den indexeras då och blir tillgänglig i sök:
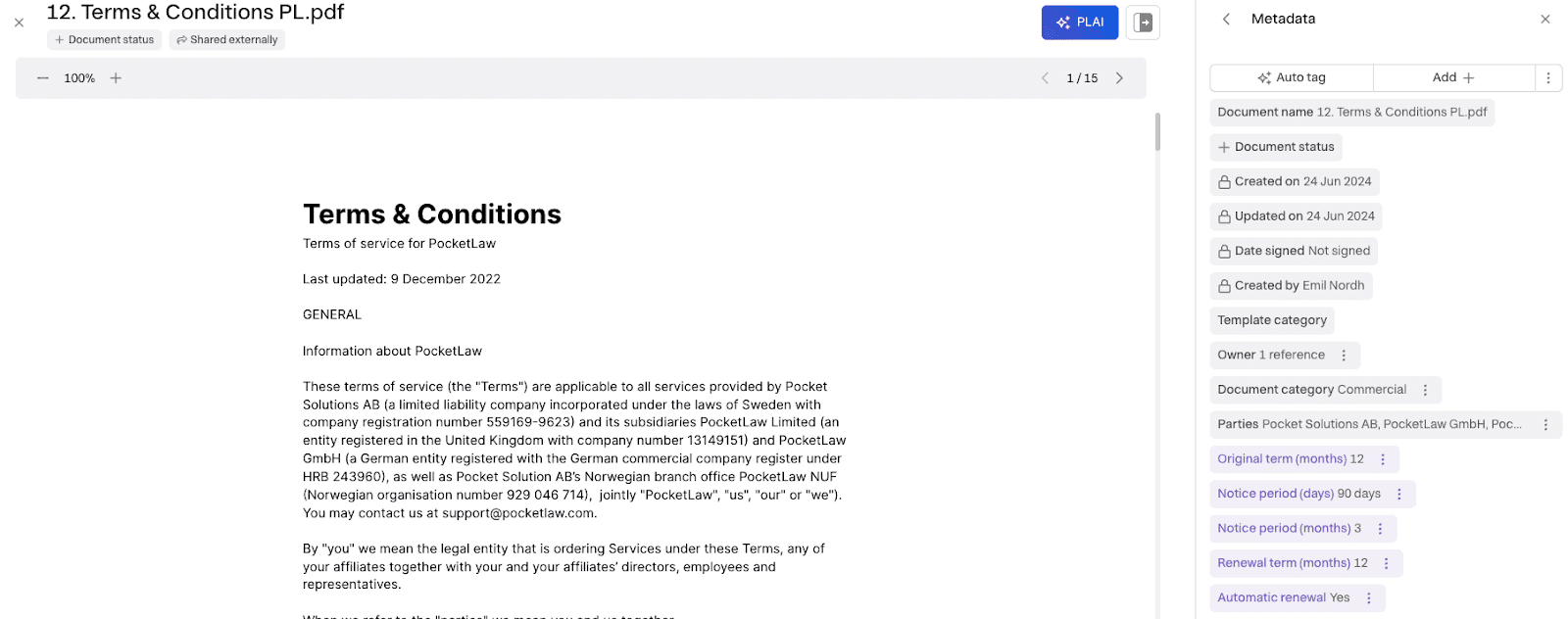
Figur 4. Exempel på verifiering av 2 metadataegenskaper.
Eller visa resonemanget för varför ett visst värde valdes; se exemplet nedan för metadataegenskapen Original Term in Months med en exakt hänvisning:
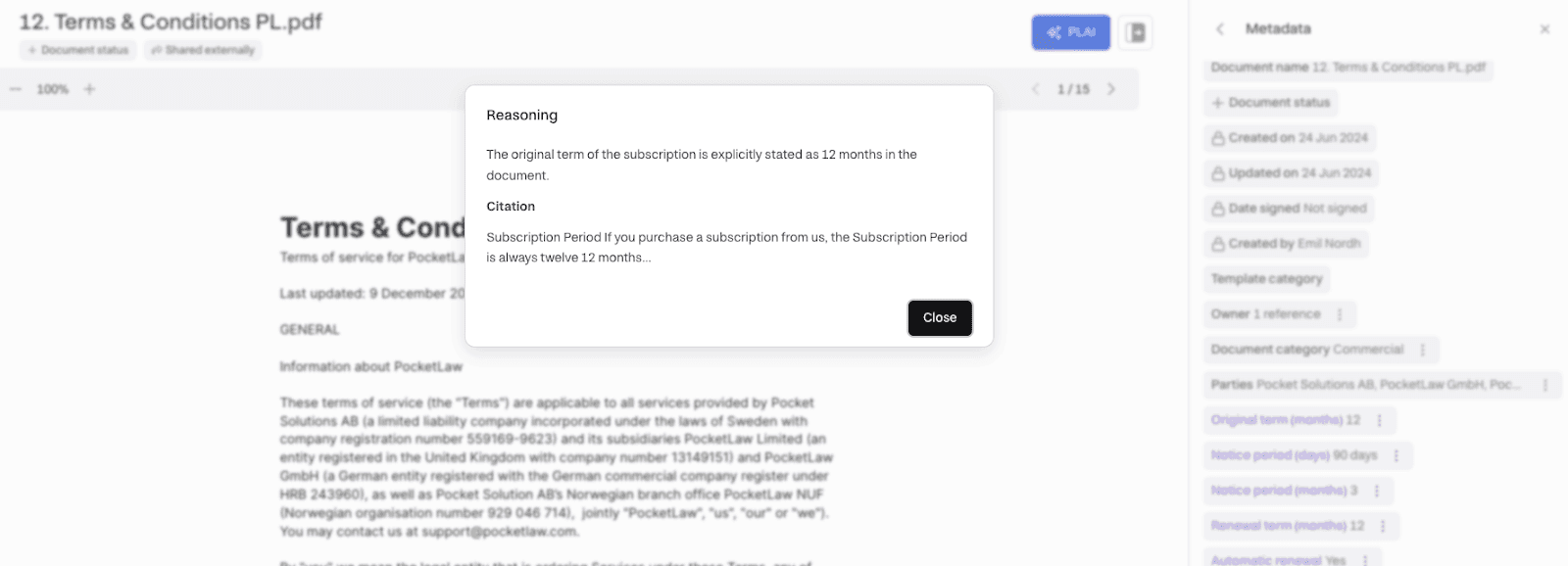
3.4 Automatiskt integrerad med vår sökmotor
Efter att taggar har identifierats och verifierats indexerar vi dem och gör dem tillgängliga för dig att söka på i Miramis-plattformen i vår sökmotor. Den är enkelt tillgänglig via CMD + K som visas nedan:
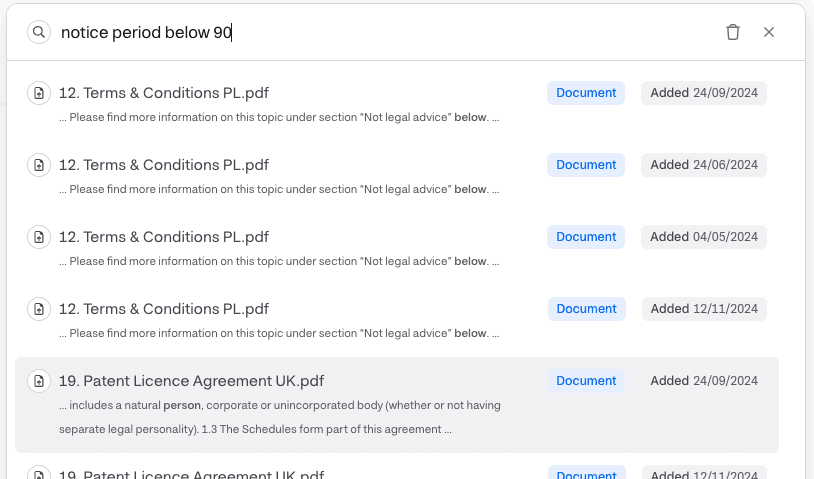
Figur 5. Exempelsökning med några av de indexerade metadataegenskaperna.
4. Läs mer om hur AI kan hjälpa till med metadataextraktion
Låt inte manuell taggning sinka dig – extrahera all din nyckeldata på några sekunder och lås upp hela potentialen i dina juridiska arbetsflöden med Miramis avancerade AI-drivna repository-lösning för automatisk taggning. Oavsett om du hanterar ett fåtal avtal eller tusentals är vår plattform byggd för att hjälpa dig att effektivisera dina processer, minska manuellt arbete och förbättra insynen i avtal och regelefterlevnad.
Om du vill se hur AI kan hjälpa till och förändra din taggningsprocess:
Boka en demo: Se våra kraftfulla AI-funktioner för taggning i praktiken och upptäck hur de kan förändra er juridiska verksamhet.
Prata med en expert: Kontakta vårt team för att se hur Miramis kan anpassas till dina specifika behov.
Ansvarsfriskrivning:
Observera: Miramis Technologies ersätter inte en advokat eller advokatbyrå. Om du har juridiska frågor om innehållet på den här sidan, kontakta en kvalificerad jurist.