In today’s fast-paced legal environment, extracting critical information is crucial for compliance and streamlining workflows, reducing manual effort, and improving contract visibility and accessibility. Extracting key and critical data from various text sources has been a significant problem, especially in the legal domain, where vital information such as parties, governing law, notice date, contract value, and so forth have different legal implications. Before large language models (LLMs), traditional NLP-based techniques for named entity recognition were the default solution. By using LLMs, we can extract critical legal information with the click of a button to improve your search and filtering experience on the Miramis (formerly Pocketlaw) platform. In this article, we will explore how AI can rapidly extract key data from contracts, emphasize the importance of contextual relevance within the legal space, highlight the critical role of human intervention, and demonstrate how Miramis can transform your data insights.
1. How can AI assist with metadata extraction
LLMs excel at extracting various metadata properties from a text source, often a contract, in the legal setting. Due to their training, they are particularly good at recognizing and extracting key named entities from a contract.
Named Entity Recognition (NER) is a task of Natural Language Processing (NLP) that involves identifying and classifying named entities in a text into predefined categories such as person names, organizations, locations, and others. NER aims to extract structured information from unstructured text data and represent it in a machine-readable format. Approaches typically use BIO notation, differentiating entities' beginning (B) and the inside (I). O is used for non-entity tokens. One example below from a legal document could be:
“This agreement, dated January 1, 2024, is made between Acme Corporation and John Smith.”
Which would result in the entities below:
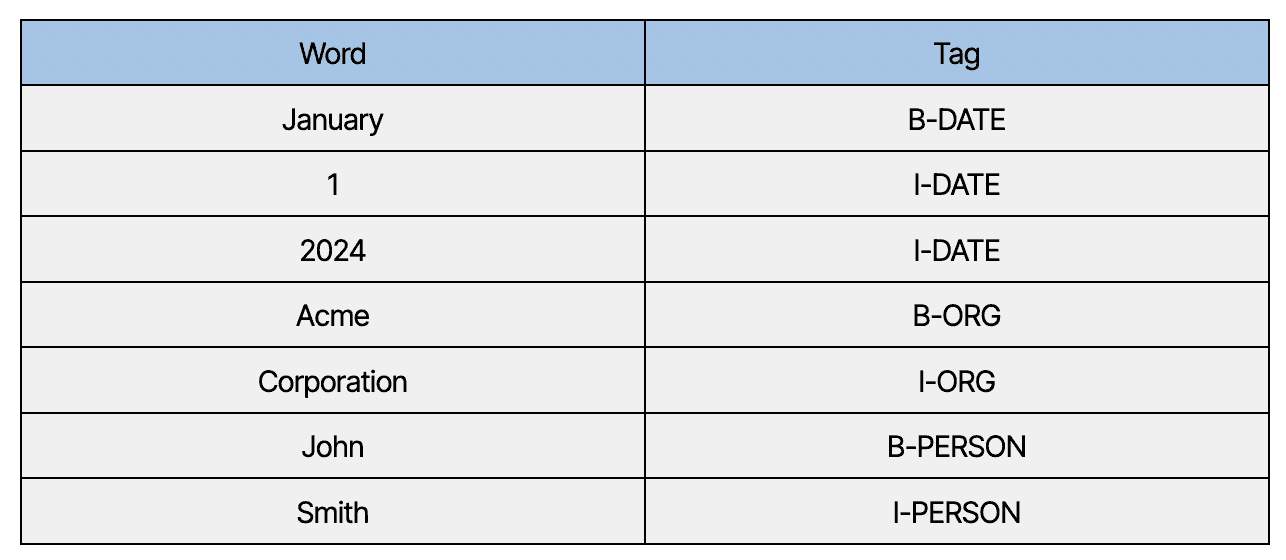
DATE: “January 1, 2024” – The beginning (B) of the date is “January,” followed by inside (I) tags for “1” and “2024.”
ORG (Organization): “Acme Corporation” – “Acme” is the beginning of the organization name, with “Corporation” as the inside part.
PERSON: “John Smith” – “John” is the beginning, and “Smith” is the inside of the person’s name.
This structured tagging (using BIO notation) allows us to map unstructured text into searchable metadata fields. Traditional NER methods require extensive labeled datasets and significant engineering effort to achieve accuracy. LLMs, however, can perform this task accurately with minimal setup, rapidly identifying entities and adapting to complex legal language.
Leveraging LLMs for metadata extraction streamlines legal workflows, making it faster and easier to locate critical information across large document collections. This transforms how legal professionals interact with contract data.
2. Important Considerations for an AI auto-tagging solution
Now that we know how AI can extract critical information from legal documents and how this information can be used, we can dive into some important considerations for a legal AI auto-tagging solution.
2.1 Accuracy and Precision
Ensuring high accuracy in tagging is critical for legal applications as inaccurate tagging can lead to significant risk, from misinterpreted terms to overlooked clauses that may have financial or legal consequences. The concretize the solution should be able to:
Minimize false positives (incorrectly tagged entities) and false negatives (missed entities)
Accurately handle diverse legal terms and nuance language variations
Be backed by rigorous testing with domain-curated legal datasets to improve accuracy and precision continuously.
At Miramis, this is part of our modus operandi. Together with our domain experts, we ensure that our tagging solution is legally sound and accurate. Of course, this continuous process has made our repository solution best-in-class.
2.2 Language, Contract, and Jurisdiction Agnostic
An effective AI solution must be versatile, handling documents across language, contract types, and jurisdictions. Legal terms and interpretations can also vary. Some key aspects we see:
It supports multiple languages and is adaptable for use across different languages.
Work seamlessly with various contract types, from NDAs to marketing agreements.
Recognize jurisdictional differences and adapt tagging appropriately.
At Miramis, we use the latest and greatest LLMs with a wide range of language capabilities, from Swedish, English to Arabic and many other languages.
2.3 Handle Ambiguity and Context Variability
Legal language is often very context-dependent and ambiguous, and terms can have different meanings and implications based on the context. For example, “effective date” can mean different things, whether the contract is an employment contract, sales agreement, or NDA. A robust AI tagging should should:
Detect subtle context shifts within documents to tag entities accurately.
Adapt to different document category types and clauses without rigid templates or examples.
Leverage and understand the semantics and context of the document based on surrounding text or adjacent documents.
At Miramis, we use the latest and greatest LLMs, employ best-in-class prompt engineering techniques, and refine the context used to extract and handle the various legal nuances of contracts. This is something we do in tandem with our legal domain experts. It is tempting to think that providing an example schema for what the LLM should extract is good enough. In our experience, this is not good enough for legal practices. You might get 80% of the way in the best case, but to reach the high 90s in terms of accuracy, much more effort and work is needed to guarantee the best experience for you and your legal team.
2.4 Model Interpretability and Transparency
Transparency is essential in legal applications, as professionals need to trust the AI’s tagging decisions. The solution should allow users to understand the reasoning behind why certain tags are extracted, enhancing trust and usability. Key aspects are:
Provide clear explanations and reasoning for why specific entities are tagged, especially for ambiguous terms.
Users can review, verify, and adjust tags with minimal effort when necessary.
The solution should provide citations and references for where the entity was extracted in the document.
These essential features are a must-have here at Miramis to improve the trust and usability of these AI and LLM-based systems. We don’t trigger any workflows or update our search engine until you have confirmed that the tags are according to your expectations, giving you more control and power. Thus, it minimizes the risk of faulty extraction that could lead to costly legal mistakes.
2.5 Integration with existing workflows
For an AI tagging solution to be precious, it must fit seamlessly into existing legal workflows. Legal teams might be entrenched in specific document management or contract management systems, where the AI tagging solution should:
Integrate smoothly with common legal platforms, document management systems, and CLMs.
Minimize disruption by aligning with established document review, storage, and retrieval processes.
Create actionable insights and custom dashboards using the provided metadata tags.
We have built Miramis as a one-stop shop for your CLM, which needs to be powered by our AI features. To support you in the entire document lifecycle from creating a template, drafting a document, receiving and sending or editing contracts with other parties, signing contracts, and extracting metadata from contracts. This is to (1) index them on our platform, (2) make them searchable for you, and (3) use critical metadata for actionable insights from setting alerts to building custom dashboards.
With these features, metadata extraction becomes just one piece of a complete solution, empowering legal teams to make data-informed decisions throughout the contract lifecycle.
2.6 Handle large batches of documents
Handling large batches of documents requires AI to maintain efficiency and accuracy across a high volume of contracts, ensuring that even bulk processing can yield reliable, actionable metadata. Key aspects are:
Being able to tag one or many documents in a reasonable time
Being able to extract text from various document types such as PDFs, docx etc
Being able to rerun tagging for documents when needed
At Miramis, we handle processing at scale as a part of our DNA. Our AI auto-tagging solution works equally well on one document or 1000s of documents of various types such as PDF and docx. Our text extraction pipeline ensures that all critical information in a document will be ingested and prepared for metadata extraction, whether it be images, tables, or a mixed format in a specific document.
3. How Miramis (formerly Miramis) extractions critical Legal metadata at scale
At Miramis, we leverage cutting-edge technology, such as the latest LLMs, with legal domain expertise to ensure that metadata extraction is efficient, scalable, and highly precise. Below, we will dive deep into how we do this at Miramis.
3.1 Supporting many legal metadata properties
At Miramis, we support many relevant legal metadata properties, from Document Category, Parties, Notice Period to Probationary Period. Many of these properties are also AI taggable, and we support AI tagging extraction for thousands of documents.
See the example below of how this looks on the platform.
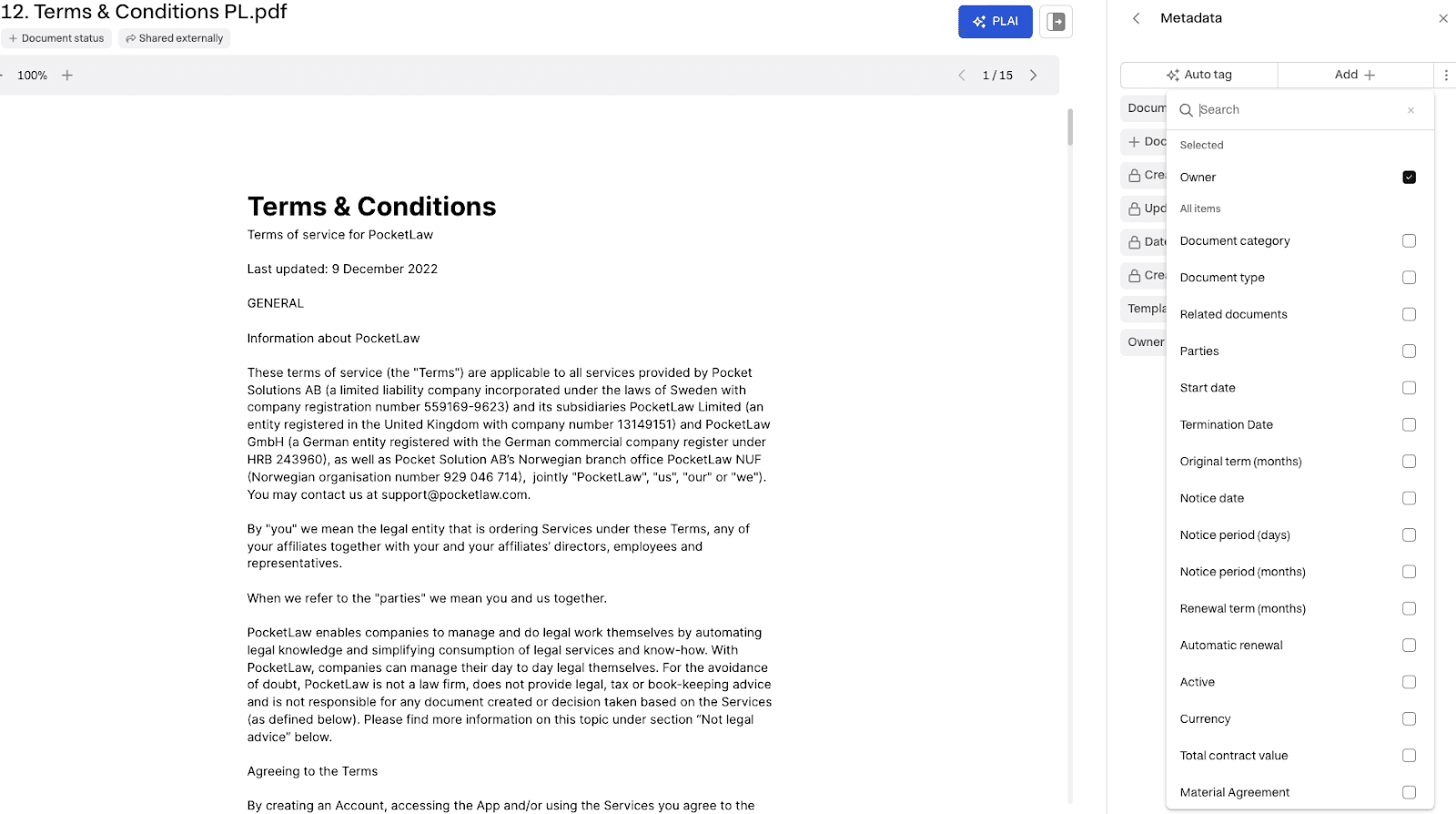
Fig 1. Examples of available tags.
As you can see, some tags are set as soon as you upload a document, which we call system-set properties. These are various metadata properties that are part of the document metadata when it is loaded into the Miramis platform. Apart from the system set properties, you can add any property found in the dropdown list. The majority of these are also tagged by AI automatically.
When AI tags are added, you will see them in purple below for further actions:
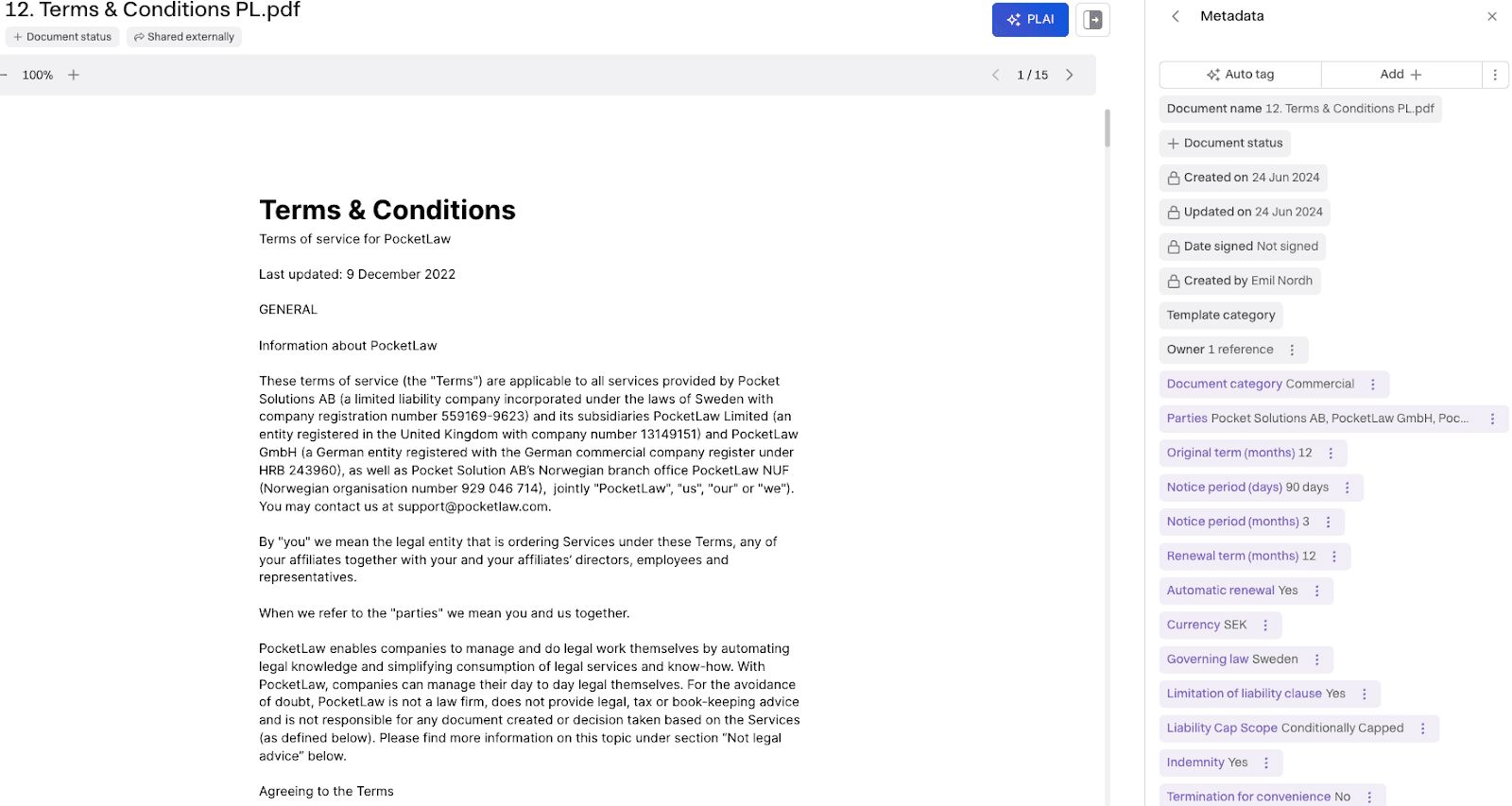
Fig 2. AI auto-tagged tags are shown in purple.
3.2 Using advanced prompt engineering techniques
To get the highest accuracy using LLMs to extract metadata, we employ a wide range of prompt engineering techniques and guardrails to ensure the highest quality of each extraction. Although most LLM providers support structured output extraction (see, e.g., OpenAI's relatively recent announcement) from a JSON schema, we have noticed in a legal context that more than providing the schema is needed to get the highest accuracy and precision.
Some of the techniques we use are:
Incorporating domain knowledge for each property with few-shot examples
Chain-of-Thought reasoning
Prompt Chaining to divide the extraction problem into sub-problems
Self-consistency, reflection, and correction
This and various guardrails are implemented in our backend to minimize and mitigate potential errors and hallucinations. Using these techniques, we got high accuracy for a wide range of properties and document categories.
3.3 Human-in-the-loop verification at all times
To improve the reliability and trust of the system, we also employ the following for you as an end-user:
Each tag needs to be verified before it can be indexed and used in our search engine
All tags have a reasoning and citation field that makes verification a seamless process
This is how it looks in the platform for these various mechanisms:
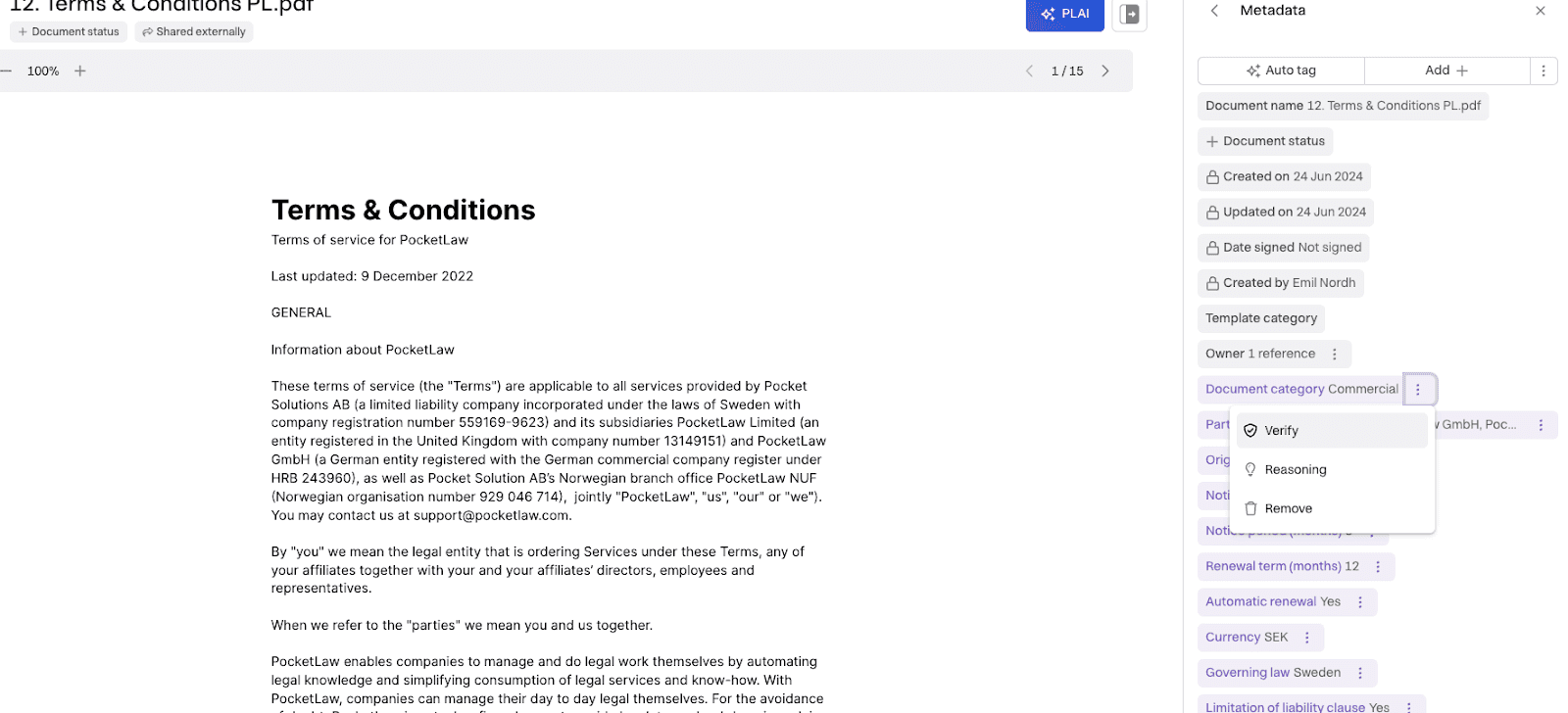
Fig 3. Human-in-the-loop controls for metadata tags.
You can verify, reason, or remove the AI tag when clicking on the three dots. Verify is used to verify the AI tag; reasoning shows the reasoning and a citation if available. Finally, remove is used to remove the tag. This can be handy if you want to completely re-tag everything in a document that has already been verified, for instance, if the document context has changed drastically.
When clicking on the verify button, the tag turns gray, representing the system-set properties, which are then indexed and made available in search:
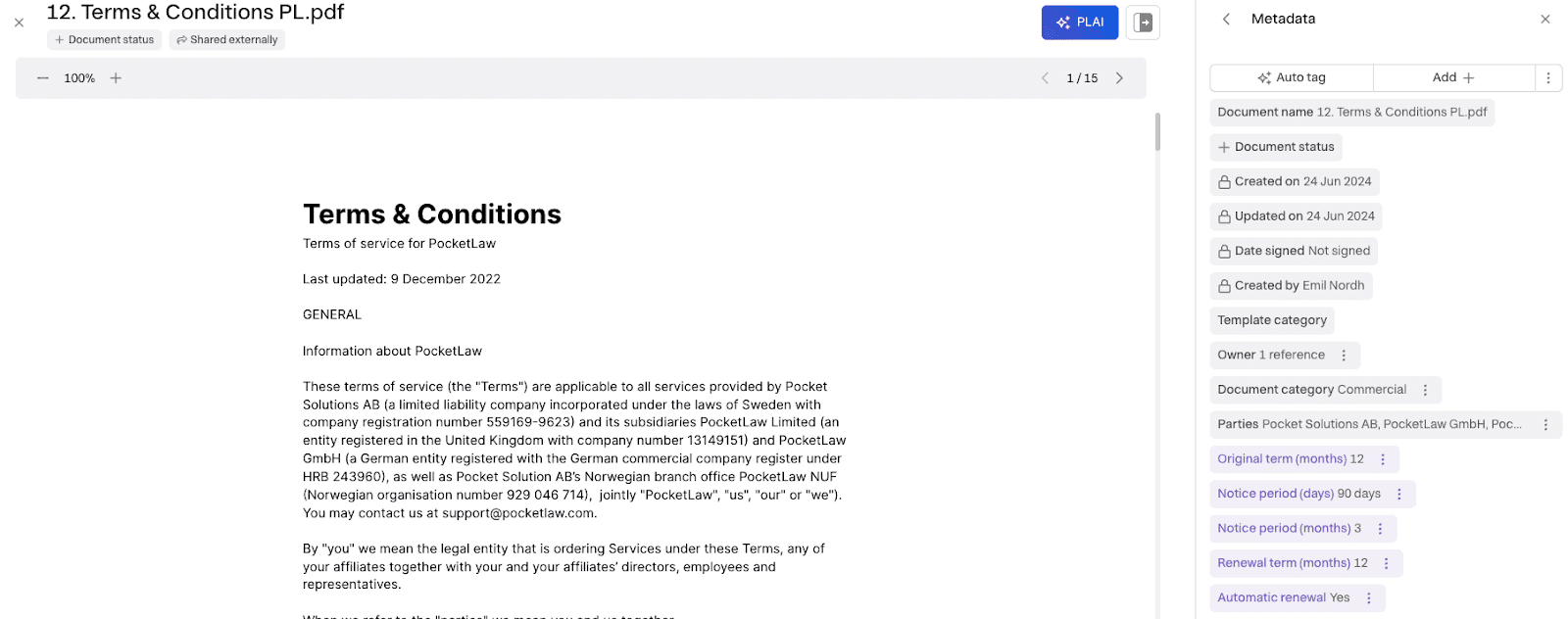
Fig 4. Example of verification of 2 metadata properties.
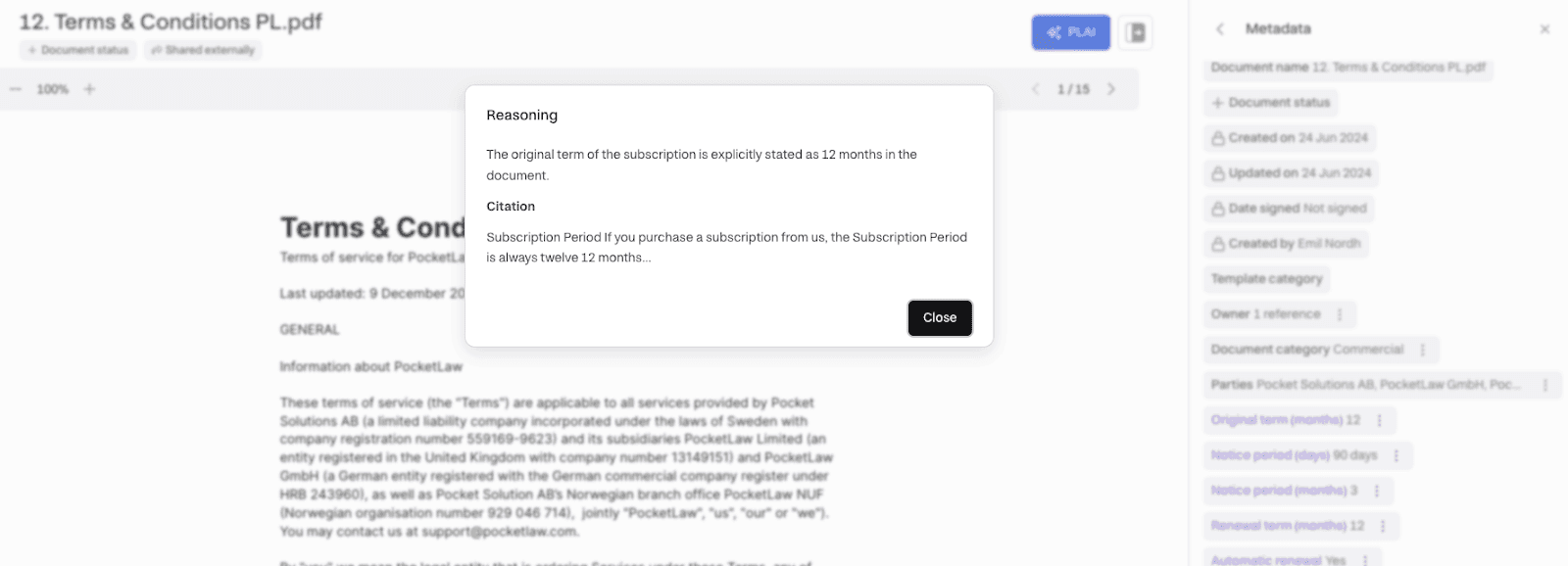
Or show the reasoning for why a particular value was picked; see the example below for the Original Term in Months metadata property with a precise citation:
3.4 Automatically integrated with our search engine
After tags have been identified and verified, we index them and make them available for you to search on the Miramis platform in our search engine. Which is easily accessible via CMD + K as shown below:
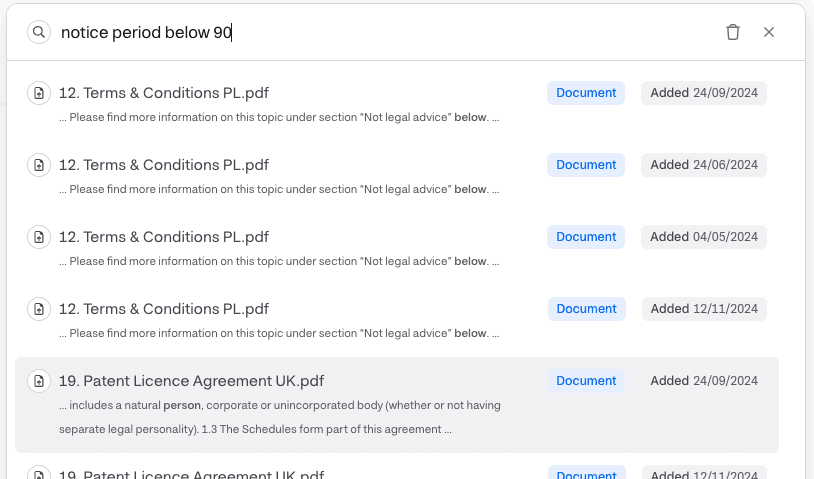
Fig 5. Example search using some of the index metadata properties.
4. Learn more about how AI can assist with metadata extraction
Don’t let manual tagging slow you down - extract all your key data in seconds and unlock the full potential of your legal workflows with Miramis' cutting-edge AI auto-tagging repository solution. Whether you’re managing a handful of contracts or thousands, our platform is designed to help you streamline your processes, reduce manual work, and improve contract visibility and compliance.
If you are interested in seeing how AI can help and revolutionize your tag process:
Book a demo: See our powerful AI tagging features in action and discover how they can revolutionize your legal operations.
Talk to an expert: Connect with our team to learn how Miramis can be customized to your specific needs.
Disclaimer:
Please note: Miramis Technologies is not a substitute for an attorney or law firm. So, should you have any legal questions on the content of this page, please get in touch with a qualified legal professional.